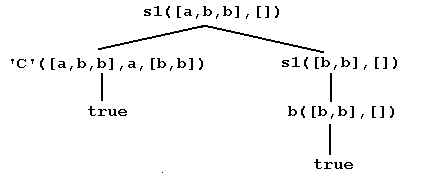
Fig. 7.1.1
Prolog has the capacity to load definite clause grammar rules (DCG rules) and automatically convert them to Prolog parsing rules. As an illustration, consider a typical kind of left-regular grammar for the regular language a*bb ...
For Prolog, rewrite this grammar something like this ...S --> a S S --> B B --> bC C --> b
Notice that we have collapsed the last two rules into one. Do not be confused by the use of 'b' as both a nonterminal symbol and as a terminal symbol. In Prolog grammars, any use as a terminal symbol must always be within brackets '[..]'.s1 --> [a], s1. s1 --> b. b --> [b,b].
When loaded into Prolog, these grammar rules are translated into the following clauses
'C' is a built-in Prolog predicate whose intuitive meaning is "connects" and whose definition is ...s1(A,B) :- 'C'(A,a,C), s1(C,B). s1(A,B) :- b(A,B). b([b,b|A],A).
One can use the grammer as a parser ...'C'([A|B],A,B).
... but not as a generator ...?- 'C'([1,2,3],1,[2,3]). Yes ?- s1([a,a,a,b,b],[]). Yes ?- s1([a,b[,[]). No
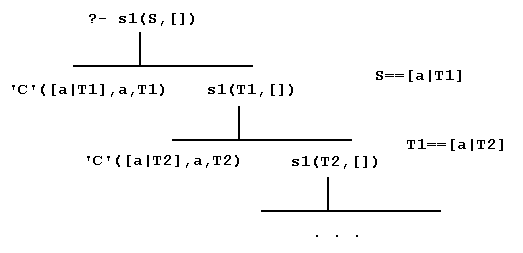
The use of a Prolog grammar as a generator is uncommon. We will see that most useful grammars are specified for the sake of parsing, not expression generation.?- s1(S,[]). ... (infinite loop)
Here is a clause tree, with root s1([a,b,b],[]) ...
The reason that the Prolog (left-regular) grammar cannot be used to generate sequences is that the grammar is right-recursive. There could be any number of a's at the beginning of the sequence S, and the first clause for s1 could be used repeatedly. The following derivation reveals the problem ...
With this grammar ...s_1 --> a, b. a --> []. % empty production a --> [a],a. b --> [b,b].
By the way, the empty production (2nd grammar rule) will be loaded as the following clause -- which means either consume nothing (when parsing) or generate nothing ...?- s_1(S,[]). S = [b,b] ; S = [a,b,b] ; S = [a,a,b,b] ; ...
a(A,A).
Exercise 7.1 Explain why this grammar will generate sequences.
Exercise 7.2 Specify a Prolog grammar for the language of sequences consisting of a's followed by an equal number(zero or more) of b's. Recall that this language is context-free but not regular.
For non-context-free languages one can use Prolog grammars with parameters -- a clever device -- bracketed, embedded, Prolog goals -- for specifying context (or other) information. For example, consider the following Prolog grammar for sequences of equal numbers of a's followed by b's followed by c's ...
s2 --> a(N), b(N), c(N).
a(0) --> [].
a(M) --> [a],
a(N),
{M is N + 1}. % embedded Prolog Goal
b(0) --> [].
b(M) --> [b],
b(N),
{M is N + 1}.
c(0) --> [].
c(M) --> [c],
c(N),
{M is N + 1}.
Exercise 7.1.3 Load the s2 grammar and test is
on various inputs, both as parser and generator. Also,
look at the Prolog listing so as to see how the embedded
goals are handled.